在线咨询:
(PC端)
 (手机端)
(手机端)
大家已经知道,C源程序需要经过编译和链接才能生成可执行文件。实际上,在C源程序进行编译的第一遍扫描(词法扫描和语法分析)之前,首先需要经历一个预处理阶段。预处理将由预处理程序负责完成。当编译器对一个源文件进行编译时,系统将自动引用预处理程序对源程序中的预处理部分作处理,处理完毕再进入对源程序的编译。
程序在编译预处理的阶段,不仅提供了宏定义的功能,还提供了文件包含以及条件编译的功能。文件包含在讲解“头文件”时已经提及,本章将详细介绍预处理中的“宏定义”,详细介绍预处理功能中的“条件编译”。
在C语言源程序中,宏定义是指用一个标志符代表一个字符串,该标志符就称为宏名。在程序编译预处理阶段,所有宏名将会被替换为宏定义中的字符串,这个操作被成为宏展开。
宏定义分为不带参数的宏定义和带参数的宏定义,其定义格式如下:
不带参数格式:#define
标识符
字符串
带参数的格式:#define
标识符(参数表)
字符串
先来看不带参数的宏定义,比如在计算圆的面积的时候,经常使用PI的值。于是可以把PI的值利用宏定义来表示。
#define PI 3.14
float calccirclearea(float r)
{
return PI*r*r;
}
那么,在进行预处理阶段,预处理程序会把代码中的宏名替换为3.14,即代码变为:
float calccirclearea(float r)
{
return
3.14*r*r;
}
既然预处理是将PI替换为3.14,那么为什么不直接把3.14写进代码,这样就可以免去了预处理的时候进行替换呢?
首先,使用宏名PI在编写程序的时候代替3.14,这样可以提高程序的可读性,这是其一。其二,如果PI的值在程序中有多次引用,一旦PI的值需要在精度方面进行修改,那么使用了宏之后,只需要在宏定义的时候进行一次修改就可,而没有使用宏定义的时候,就需要在程序中多处修改。
接下来再看带参数的宏的定义方法。比如,在程序里经常会遇到计算2个值中的最大值的算法问题。这个算法问题可以用宏定义如下:
#define MAX(X, Y) (X) > (Y) ? (X) : (Y)
void main(void)
{
int a = 10;
int b = 11;
int c = MAX(a,
b);
printf(“max =
%d\n”, c);
}
上面的程序在预处理阶段会被替换为下面的代码:
void main(void)
{
int a = 10;
int b = 11;
int c
=(a)>(b)?(a):(b);
printf(“max =
%d\n”, c);
}
上面分别介绍了用宏来定义一个常量和带参的宏定义的情况。但它们都只有一条语句。现在来看用宏定义一个多条语句的宏。在程序设计中,另外一个很经典的算法就是将两个数进行交换。比如有2个整数:
int a = 10;
int b = 20;
交换后,a的值为20,b的值为10。在程序里面,必须要使用一个临时变量,来先把a的值保存起来,然后再把b的值赋给a,再把临时变量保存起来的a的值赋值给b。如果不用临时变量把a的值保存起来,那么当把b的值赋给a的时候,a的值就会丢失。
错误的写法如下:
a = b; //a的值丢失
b = a;//a和b的值最终都是b的值
正确的写法:
int tmp = a; //使用tmp变量保存a的值
a = b;
b = tmp;
上面的算法可以用宏来定义如下:
#define SWAP(a,b)
{ \
int tmp; \
tmp = a; \
a= b; \
b = tmp; \
}
上面的宏定义中,每行语句都用一个’\’来连接,用来将两个int类型的整数交换。然后在程序中使用这个宏定义如下:
void main(void)
{
int a = 10;
int b = 20;
SWAP(a, b);
printf(“a=%d, b=%d\n”, a, b);
}
这种对于多条语句的定义方法,虽然在一般情况下不会出现什么问题。但是,来看看下面的条件语句:
If (x>y)
SWAP(a, b);
else
SWAP(a,b);
如果对上面的条件语句进行宏展开,就得到了下面的程序:
if (x>y)
{
int tmp;
tmp = a;
a= b;
b = tmp;
};//注意这里的分号,将if和else拆开了,else无法和if配对
else
{
int tmp;
tmp = a;
a= b;
b = tmp;
};
很显然,else语句和if语句被分号;分割,出现一个语法错误,即else语句找不到if语句与之配对。
于是,当包含多条语句的宏,一般采用do-while(0)的格式来定义,即在语句外面加上一个do-while(0)来包装:
#define SWAP(a,b)
do { \
int tmp; \
tmp = a; \
a= b; \
b = tmp; \
}while(0)
这样,上面的程序展开之后:
if (x>y)
do{
int tmp;
tmp = a;
a= b;
b = tmp;
}while(0);
else
do {
int tmp;
tmp = a;
a= b;
b = tmp;
}while(0);
这样do-while(0)本身就只是一条语句,宏定义中的语句也只执行一次就退出了do-while循环,也避免了上面宏定义出现的一个特殊错误。
我们知道,宏在编译前预处理阶段,就已经完成了替换,而且替换是一个简单的替换,对宏的参数不会做任何的计算。比如定义一个求2个数中最大值的宏:
#define MAX(a,b) ((a)>(b)?(a):(b))
那么把下面的宏展开:
MAX(1+2,value)则会把它替换成:
((1+2)>(value)?(1+2):(value))
不要错误的认为:
MAX(1+2,value),会先计算1+2为3,即MAX(1+2,value)àMAX(3,value)。这是不对的。宏不像函数,不会计算1+2,而是直接用1+2去替换表达式中的a。
1.#和##的用法
对于#,宏会把#的内容当作一个字符串来替换。比如:
#define CAT(c) “
于是:CAT(abc)就会被替换成:”
#define STR(c) #c
于是:STR(a)
就会被替换成:”a”
对于##,用于把两侧的参数合并为一个符号。比如:
#define combine(a,b,c) a##b##c
于是:combine(1,2,3)就会被替换成:123;而combine(“1”,”
2.求结构体成员偏移
#define offsetof(s,m) (size_t)&(((s
*)0)->m)
结构体成员偏移是指该成员距离结构体起始地址的距离。上面的宏定义中,s为结构体类型,m为结构体中的成员,比如:
typedef struct
{
int a;
char c;
}mysruct;
printf(“offset of c:%d\n”, offsetof(mystruct,c));//打印出c在结构体mystruct中的偏移。
3.计算数组长度
#define ARRAYSIZE(a) sizeof(a)/sizeof(a[0])
上面的宏定义,可以计算出一个数组元素的个数,比如:
int arr[]={1,3,7,11,2,6,10};
printf(“len of arr:%d\n”,ARRAYSIZE(arr));
4.软件工程中宏的应用:
文件的路径最大长度:
#define MAX_PATH 260
char szPath[MAX_PATH] = {0};
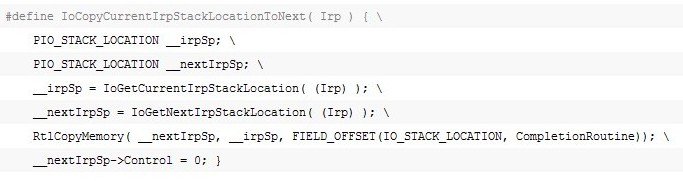
WDK中IRP操作方法IoCopyCurrentIrpStackLocationToNext(Irp)也是一个宏定义:
(1)宏名一般用大写
(2)使用宏可提高程序的通用性和易读性,减少不一致性,减少输入错误和便于修改。例如:数组大小常用宏定义
(3)预处理是在编译之前的处理,而编译工作的任务之一就是语法检查,预处理不做语法检查。
(4)宏定义末尾不加分号;
(5)宏定义写在函数的花括号外边,作用域为其后的程序,通常在文件的最开头。
(6)可以用#undef命令终止宏定义的作用域
(7)宏定义允许嵌套
(8)字符串" "中永远不包含宏
(9)宏定义不分配内存,变量定义分配内存。
(10)宏定义不存在类型问题,它的参数也是无类型的。
(1)#define NAME "zhangyuncong"
程序中有"NAME"则,它会不会被替换呢?
(2)#define 0x abcd
可以吗?也就是说,可不可以用不是标识符的字母替换成别的东西?
(3)#define NAME "zhang
这个可以吗?
(4)#define NAME "zhangyuncong"
程序中有上面的宏定义,并且,程序里有句:
NAMELIST这样,会不会被替换成"zhangyuncong"LIST
四个题答案都是十分明确的。
第一个,""内的东西不会被宏替换。这一点应该大都知道。
第二个,宏定义前面的那个必须是合法的用户标识符
第三个,宏定义也不是说后面东西随便写,不能把字符串的两个""拆开。
第四个:只替换标识符,不替换别的东西。NAMELIST整体是个标识符,而没有NAME标识符,所以不替换。
也就是说,这种情况下记住:#define第一位置第二位置
(1) 不替换程序中字符串里的东西。
(2) 第一位置只能是合法的标识符(可以是关键字)
(3) 第二位置如果有字符串,必须把""配对。
(4) 只替换与第一位置完全相同的标识符
还有就是老生常谈的话:记住这是简单的替换而已,不要在中间计算结果,一定要替换出表达式之后再算。
2、 带参宏一般用法
比如#define MAX(a,b) ((a)>(b)?(a):(b))
则遇到MAX(1+2,value)则会把它替换成:
((1+2)>(value)?(1+2):(value))
注意事项和无参宏差不多。
但还是应注意
#define FUN(a) "a"
则,输入FUN(345)会被替换成什么?
其实,如果这么写,无论宏的实参是什么,都不会影响其被替换成"a"的命运。
也就是说,""内的字符不被当成形参,即使它和一模一样。
那么,你会问了,我要是想让这里输入FUN(345)它就替换成"345"该怎么实现呢?
请看下面关于#的用法
3、 有参宏定义中#的用法
#define STR(str) #str
#用于把宏定义中的参数两端加上字符串的""
比如,这里STR(my#name)会被替换成"my#name"
一般由任意字符都可以做形参,但以下情况会出错:
STR())这样,编译器不会把“)”当成STR()的参数。
STR(,)同上,编译器不会把“,”当成STR的参数。
STR(A,B)如果实参过多,则编译器会把多余的参数舍去。(VC++2008为例)
STR((A,B))会被解读为实参为:(A,B),而不是被解读为两个实参,第一个是(A第二个是B)。
4、 有参宏定义中##的用法
#define WIDE(str) L##str
则会将形参str的前面加上L
比如:WIDE("abc")就会被替换成L"abc"
如果有#defineFUN(a,b) vo##a##b()
那么FUN(id ma,in)会被替换成void main()
5、 多行宏定义:
#define doit(m,n) for(int i=0;i<(n);++i)\
{\
m+=i;\
}
在C++中还引入了1个新的关键字const,以代替C语言中的宏定义。那么它们与C语言中的宏有什么区别呢?
#define宏与const和inline的比较。可以通过下面的两种形式来定义圆周率:
#define PAI 3.1415926 //宏定义
const float pai = 3.1415926 //常变量
在C语言中的宏在编译的时候,编译器只对宏进行简单的替换。在C++中通过const定义一个常变量与C语言中的宏定义相比,常变量具有拥有类型、可调试、可进行参数合法性检查等优点。
宏的优点包括:宏只是在预处理的地方把代码展开,不需要额外的空间和时间方面的开销,所以调用一个宏比调用一个函数(需要进栈出栈)更有效率。但是宏容易产生二义性,也不能访问对象的私有成员,这是宏的局限。
对于宏的二义性,来看看下面的例子。从下列选项中选择不会引起二义性的宏定义是:
A、 #indefine POWER(x) x*x
B、 #indefine POWER(x) (x)*(x)
C、 #indefine POWER(x) (x*x)
D、 #indefine POWER(x) ((x)*(x))
分析:
A.#indefine POWER(x) x*x
如果调用POWER(5+6),本意是 (5+6)*(5+6)=121,实际却是:5+6*5+6=41
B.#indefine POWER(x) (x)*(x)
如果调用POWER(5+6)/POWER(5+6),本意是得到结果为1,实际却是:(5+6)*(5+6)/(5+6)*(5+6)=11*11/11*11=121
C.#indefine POWER(x)(x*x)
如果调用POWER(5+6)+POWER(5+6),本意是 (11*11)+(11*11)=121+121=242,实际却是: (5+6*5+6)+(5+6*5+6)=41+41=82
D.没有二义性。
在C语言源代码里,除了那些被注释了的代码不会被编译进程序里外,还有一种方式来规定代码是否会被编译进程序里,这就是所谓的条件编译,即代码只有符合某种条件下才能编译进程序。因为有的代码只有在某些情况下才具有被执行的可能,在其它条件下这些代码要么无法执行,要么没有必要执行。比如在Windows平台,有的函数只能在Vista以上平台才能被执行,那么在XP及以下的平台里就无法被执行,因此在XP及以下平台就没有必要将这部分代码编译进程序,有时候甚至还无法在这些平台里编译通过。又比如有的代码只能在X86平台才能执行,在X64平台下是无效的,因此也要对这部分代码进行条件编译。
条件编译可以有多种定义形式。这些定义形式详细介绍如下。
#ifdef 标识符
程序段1
#else
程序段2
#endif
在上面这种定义形式下,当标识符被定义(通过#define),那么就将程序段1编译进程序,否则,就将程序段2编译进程序。
#define WINVER 6.1
int main(void)
{
#ifdef WINVER
/*1*/ printf(“wenversion defined\n”);
#else
/*2*/ printf(“winversion not defined\n”);
#endif
return 0;
}
上面,通过宏定义将WINVER进行了定义,那么语句1而不是语句2会被编译进程序。在对WINVER进行定义的时候,即使后面不跟任何字符串(比如这里的6.1),也会被当作定义了。比如:
#define WINVER
int main(void)
{
#ifdef WINVER
/*1*/ printf(“wenversion defined\n”);
#else
/*2*/ printf(“winversion not defined\n”);
#endif
return 0;
}
这样,语句1依然会被编译进程序,而会排除语句2编译进程序。
#ifndef 标识符
程序段1
#else
程序段2
#endif
在方式2的定义下,如果标识符没有定义,那么程序段1会被编译进程序,否则程序段2会被编译进程序。
#define WINVER 6.1
int main(void)
{
#ifndef WINVER
/*1*/ printf(“wenversion defined\n”);
#else
/*2*/ printf(“winversion not defined\n”);
#endif
return 0;
}
同样以上面的程序为例子,在方式2的情况下,如果定义了WINVER,那么语句2会被编译进程序。因为前面的宏定义已经将WINVER进行了定义。
#if 常量表达式
程序段1
#else
程序段2
#endif
在定义方式3中,如果常量表达式的值为真,那么程序段1将会被编译进程序,否则,程序段2会被编译进程序。
#define DEBUG 1
int main(void)
{
int a = 5;
int b = 10;
int c = a + b;
#if DEBUG
/*1*/
printf(“c = %d\n”, c);
#endif
}
在定义了DEBUG为1的情况下,那么程序将会把语句1编译进程序,将a+b的结果在调试情况下打印输出。而一旦将DEBUG定义为0的情况下,语句1就无法编译进程序了。比如:
#define DEBUG 0
int main(void)
{
int a = 5;
int b = 10;
int c = a + b;
#if DEBUG
/*1*/ printf(“c = %d\n”, c); //此句不会被编译进程序
#endif
return 0;
}
也可以写为:
int main(void)
{
int a = 5;
int b = 10;
int c = a + b;
#if 0
/*1*/ printf(“c = %d\n”, c); //此句不会被编译进程序
#endif
return 0;
}
#if 表达式1
语句段1
#elif 表达式2
语句段2
#else
语句段3
#endif
#define X64
int main(void)
{
#if defined(X64)
printf(“x64 platform specific\n”);
#elif defined(X86)
printf(“x86 platform specific\n”);
#else
printf(“common\n”);
#endif
return 0;
}
其中defined()用来判断一个标识符是否被定义,如果定义返回为真,否则返回假。而加上个!运算符则表示取反。此外,#undef用来取消对一个标识符的定义,比如:
#ifdef A
#undef A
#endif
上面的条件编译语句,就是在A被定义的情况下取消对A的定义。这个和在头文件的写法中的方式正好相反。
现在来看在MS的库中,对LARGE_INTEGER这个64位大整数的定义,就使用了条件编译:
#if defined(MIDL_PASS)
typedef struct _LARGE_INTEGER {
#else // MIDL_PASS
typedef union _LARGE_INTEGER {
struct {
ULONG LowPart;
LONG HighPart;
} DUMMYSTRUCTNAME;
struct {
ULONG LowPart;
LONG HighPart;
} u;
#endif //MIDL_PASS
LONGLONG QuadPart;
} LARGE_INTEGER;
一旦定义了MIDL_PASS,那么LARGE_INTEGER将会被定义为:
typedef struct _LARGE_INTEGER {
LONGLONG QuadPart;
} LARGE_INTEGER;
否则会被定义为:
typedef union _LARGE_INTEGER {
struct {
ULONG LowPart;
LONG HighPart;
} DUMMYSTRUCTNAME;
struct {
ULONG LowPart;
LONG HighPart;
} u;
LONGLONG QuadPart;
} LARGE_INTEGER;
下面是一个实际工程中使用的一个条件编译的例子:
#if WINVER >= 0x0501
//
// Try to load the dynamic functions that may be available for our use.
//
SfLoadDynamicFunctions();
//
// Now get the current OS version that we will use to determine what logic
// paths to take when this driver is built to run on various OS version.
//
SfGetCurrentVersion();
#endif
#if DBG && WINVER >= 0x0501
//
// MULTIVERSION NOTE:
//
// We can only support unload for testing environments if we can enumerate
// the outstanding device objects that our driver has.
//
//
// Unload is useful for development purposes. It is not recommended for
// production versions
//
if (NULL != gSfDynamicFunctions.EnumerateDeviceObjectList) {
gSFilterDriverObject->DriverUnload = DriverUnload;
}
#endif
注意到,条件编译中提到的语句段,并不一定是一条完整的语句,比如头文件定义方式使用的其实也是条件编译。
#ifndef _FILENAME_H_
#define _FILENAME_H_
#ifdef __cplusplus
extern "C" {
#endif
…
…
...
...
...
...
#ifdef __cplusplus
}
#endif
#endif /* _FILENAME_H_ */
#ifdef __cplusplus
extern "C" {
#endif
#ifdef __cplusplus
}
#endif
 看文字不过瘾?点击我,进入周哥教IT视频教学
看文字不过瘾?点击我,进入周哥教IT视频教学
Copyright 2011-2020 © MallocFree. All rights reserved.